How to Run Llama 2 Locally: A Guide to Running Your Own ChatGPT like Large Language Model
Discover how to run Llama 2, an advanced large language model, on your own machine. With up to 70B parameters and 4k token context length, it's free and open-source for research and commercial use. Explore installation options and enjoy the power of AI locally.

Introduction
Ever thought about having the power of an advanced large language model like ChatGPT, right on your own computer? Llama 2, brought to you by Meta (formerly known as Facebook), is making that dream a reality.
Llama 2 offers a range of pre-trained and fine-tuned language models, from 7B to a whopping 70B parameters, with 40% more training data and an incredible 4k token context length. The standout feature? It's open-source and free for both research and commercial use.
This is more than just technology; it's about democratizing AI, ensuring accessibility and privacy. Whether you want to run Llama 2 locally on your machine or host it on the cloud, the choice is yours. No more sending data to external servers or relying on an internet connection.
In this guide, we'll explore various ways to install and run Llama 2 locally. Let's dive in and uncover the potential of having this powerful tool right at your fingertips.
Obtaining the Model
Before we dive into the installation, you'll need to get your hands on Llama 2. Here's how:
Option 1: Request Access from Meta's Website
You can fill out a request form on Meta's website to get access to Llama 2. Keep in mind that approval might take a few days.
Option 2: Download from Hugging Face
If you want to save time and space, you can download the already converted and quantized models from TheBloke on Hugging Face, which we'll do in this guide. We'll be using the TheBloke/Llama-2-13B-chat-GGML model for this guide.
System Requirements
Let's jump into system requirements. Here's what's generally recommended:
- At least 8 GB of RAM is suggested for the 7B models.
- At least 16 GB of RAM for the 13B models.
- At least 32 GB of RAM for the 70B models.
However, keep in mind, these are general recommendations. If layers are offloaded to the GPU, it will reduce RAM requirements and use VRAM instead. Please check the specific documentation for the model of your choice to ensure a smooth operation. Now, with your system ready, let's move on to downloading and running Llama 2 locally.
Downloading and Running Llama 2 Locally
Now that we know where to get the model from and what our system needs, it's time to download and run Llama 2 locally. Here's how you can do it:
Option 1: Using Llama.cpp
Llama.cpp is a fascinating option that allows you to run Llama 2 locally. It's a port of Llama in C/C++, making it possible to run the model using 4-bit integer quantization.
Sounds complicated? Don't worry; We've packaged everything and all you need to do is run a simple one-liner that clones the required repository and runs the script:
git clone https://github.com/sychhq/llama-cpp-setup.git && cd llama-cpp-setup && chmod +x setup.sh && ./setup.shone-liner to run llama 2 locally using llama.cpp
It will then ask you to provide information about the Llama 2 Model you want to run:
Please enter the Repository ID (default: TheBloke/Llama-2-7B-chat-GGML):
> TheBloke/Llama-2-13B-chat-GGML
Please enter the corresponding file name (default: llama-2-7b-chat.ggmlv3.q4_0.bin):
>llama-2-13b-chat.ggmlv3.q4_0.bin
...some setup output...
== Running in interactive mode. ==
- Press Ctrl+C to interject at any time.
- Press Return to return control to LLaMa.
- To return control without starting a new line, end your input with '/'.
- If you want to submit another line, end your input with '\'.
> Hi
Hey! How are you?
> Who is the founder of Facebook?
Mark Zuckerberg is the founder of Facebook.
>Sample Usage of sychhq/llama-cpp-setup
And that's your Llama 2, running locally!
Now, let's unpack what the script does:
#!/bin/bash
# Define some colors for the prompts
BLUE='\033[0;34m'
NC='\033[0m' # No Color
# Default values
DEFAULT_REPO_ID="TheBloke/Llama-2-7B-chat-GGML"
DEFAULT_FILE="llama-2-7b-chat.ggmlv3.q4_0.bin"
# Prompt the user for the Repository ID and use default if empty
echo -e "${BLUE}Please enter the Repository ID (default: ${DEFAULT_REPO_ID}):${NC}"
read REPO_ID
if [ -z "$REPO_ID" ]; then
REPO_ID=${DEFAULT_REPO_ID}
fi
# Prompt the user for the file name and use default if empty
echo -e "${BLUE}Please enter the corresponding file name (default: ${DEFAULT_FILE}):${NC}"
read FILE
if [ -z "$FILE" ]; then
FILE=${DEFAULT_FILE}
fi
# Clone the Llama.cpp repository
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
# If on an M1/M2 Mac, build with GPU support
if [[ $(uname -m) == "arm64" ]]; then
LLAMA_METAL=1 make
else
make
fi
# Check for the model and download if not present
[ ! -f models/${FILE} ] && curl -L "https://huggingface.co/${REPO_ID}/resolve/main/${FILE}" -o models/${FILE}
# Set a welcoming prompt
PROMPT="Hello! Need any assistance?"
# Run the model in interactive mode with specified parameters
./main -m ./models/${FILE} \
--color \
--ctx_size 2048 \
-n -1 \
-ins -b 256 \
--top_k 10000 \
--temp 0.2 \
--repeat_penalty 1.1 \
-t 8
sychhq/llama-cpp-setup/setup.sh
Here's a breakdown:
- We first clone the Llama.cpp repository.
- We then ask the user to provide the Model's Repository ID and the corresponding file name. If not provided, we use
TheBloke/Llama-2-7B-chat-GGMLandllama-2-7b-chat.ggmlv3.q4_0.binas defaults. - Depending on your system (M1/M2 Mac vs. Intel Mac/Linux), we build the project with or without GPU support.
- We make sure the model is available or download it.
- We then configure a friendly interaction prompt.
- Finally, we run the model with certain parameters tailored for an optimal experience.
Option 2: Using Ollama
If you're a MacOS user, Ollama provides an even more user-friendly way to get Llama 2 running on your local machine. It's a breeze to set up, and you'll be chatting with your very own language model in no time.
- Download the Ollama CLI: Head over to ollama.ai/download and download the Ollama CLI for MacOS.
- Install the 13B Llama 2 Model: Open a terminal window and run the following command to download the 13B model:
ollama pull llama2:13b
- Run Llama 2: Now, you can run Llama 2 right from the terminal. Just use:
ollama run llama2
> hi
Hello! How can I help you today?
>
And that's it! With Ollama, you've got Llama 2 running on your MacOS computer.
Option 3: Oobabooga's Text Generation WebUI
For those who prefer a graphical user interface (GUI), there's an excellent option provided by Oobabooga's Text Generation WebUI. This method adds a layer of accessibility, allowing you to interact with Llama 2 via a web-based interface.
Setting up the Text Generation WebUI
- Download the One-Click Installer: Go to Oobabooga's Text Generation WebUI on GitHub and download the one-click installer ZIP file.
- Extract the ZIP File: After downloading, extract the ZIP file to a location of your choice.
- Run the "Start" Script: Inside the extracted folder, you'll find a script beginning with "start" Double-click on it to begin the installation. If the installation does not start automatically, you may need to run the "start" script manually. You may also need to give the start script execution permissions with
chmod +x. - Launch the Web UI: Once installed, a local server will start, and you can access the web UI through your web browser.
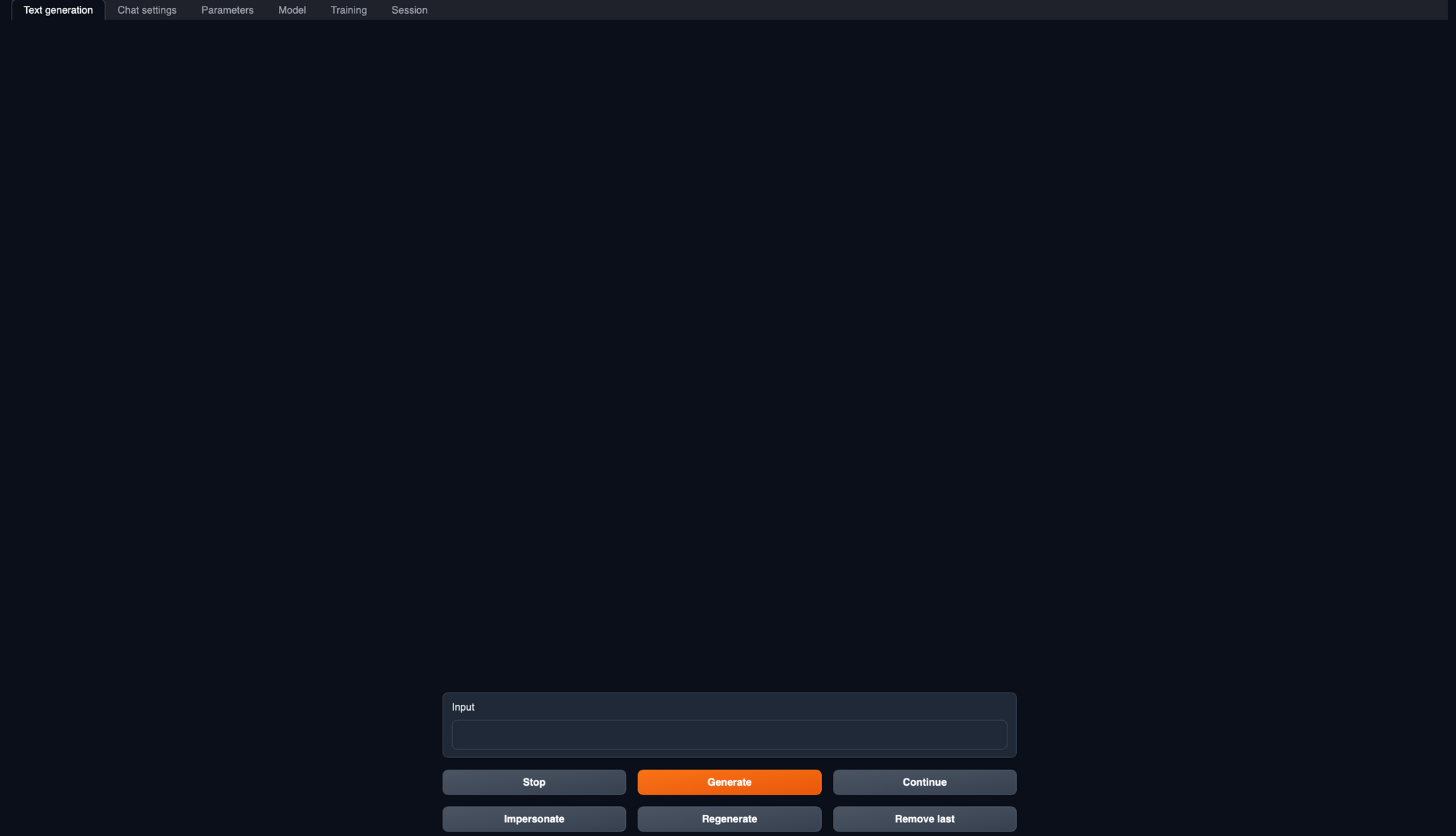
- Future Access: To launch the web UI in the future after it's already installed, simply run the "start" script again.
Downloading Llama 2
Now we need to download and interact with the Llama 2 model using Oobabooga's Text Generation WebUI.
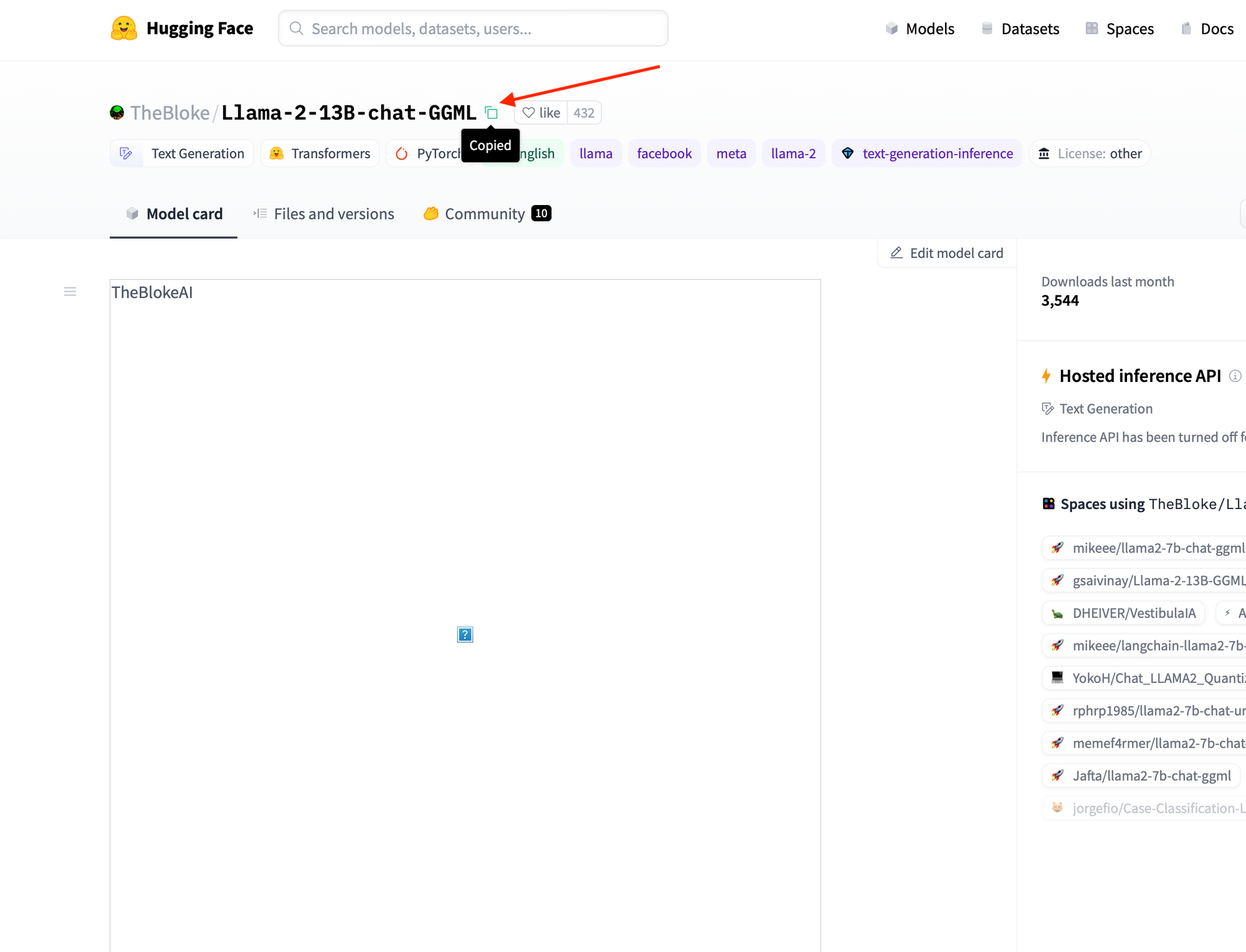
1. Copy the Model Path from Hugging Face: Head over to the Llama 2 model page on Hugging Face, and copy the model path.
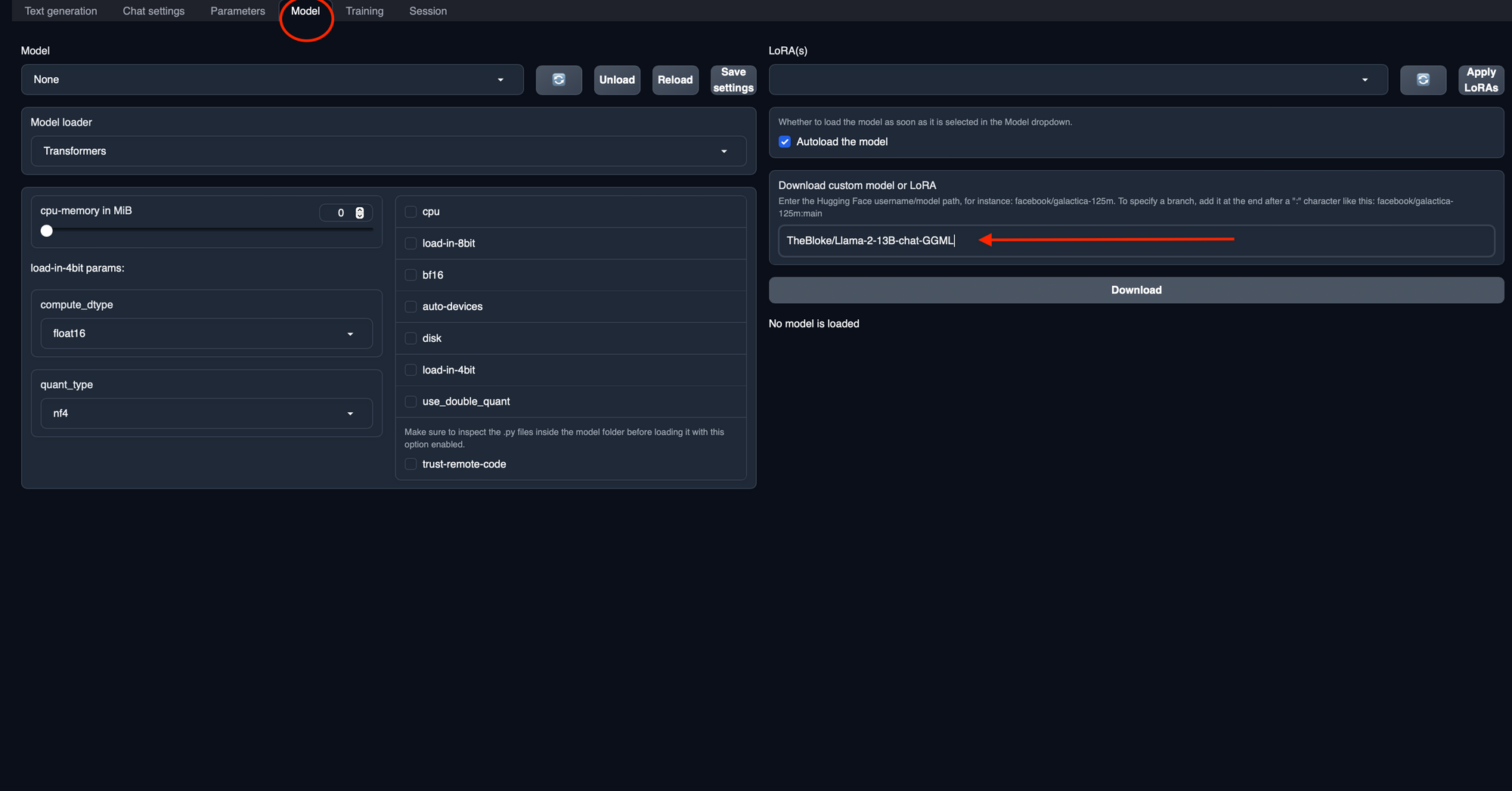
2. Navigate to the Model Tab in the Text Generation WebUI and Download it: Open Oobabooga's Text Generation WebUI in your web browser, and click on the "Model" tab. Under the section labeled "Download custom model or LoRA," paste the copied model path into the designated field, and then click the "Download" button. The download may take some time, so feel free to take a short break while it completes.
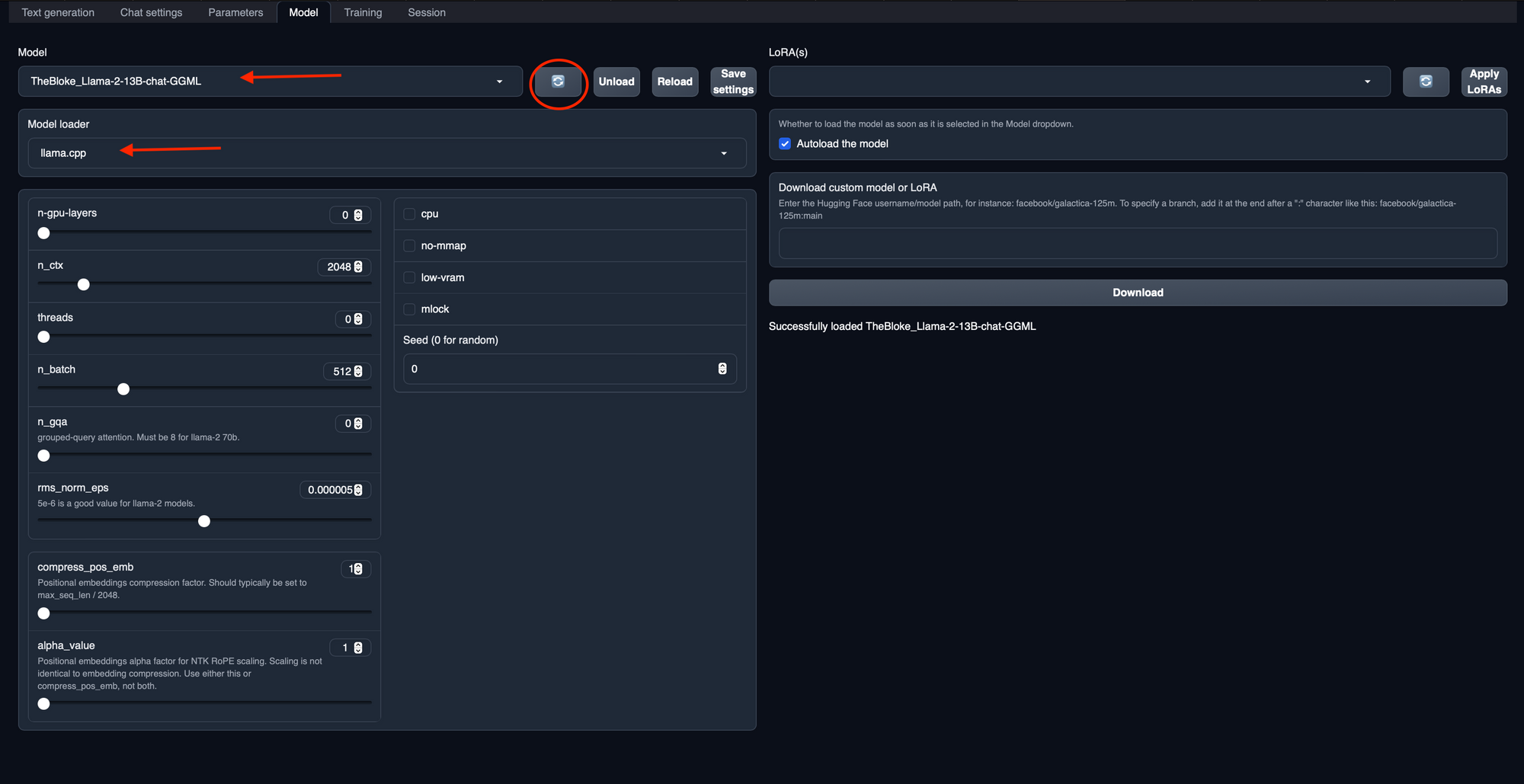
3. Select Model Loader and Load the Downloaded Model: Once the download is complete, in the same "Model" tab, find the "Model" dropdown (You may need to refresh it first using the refresh icon next to the drop down). Select and load your newly downloaded model from the list. Also select the loader as "llama.cpp" under the "Model Loader" dropdown.
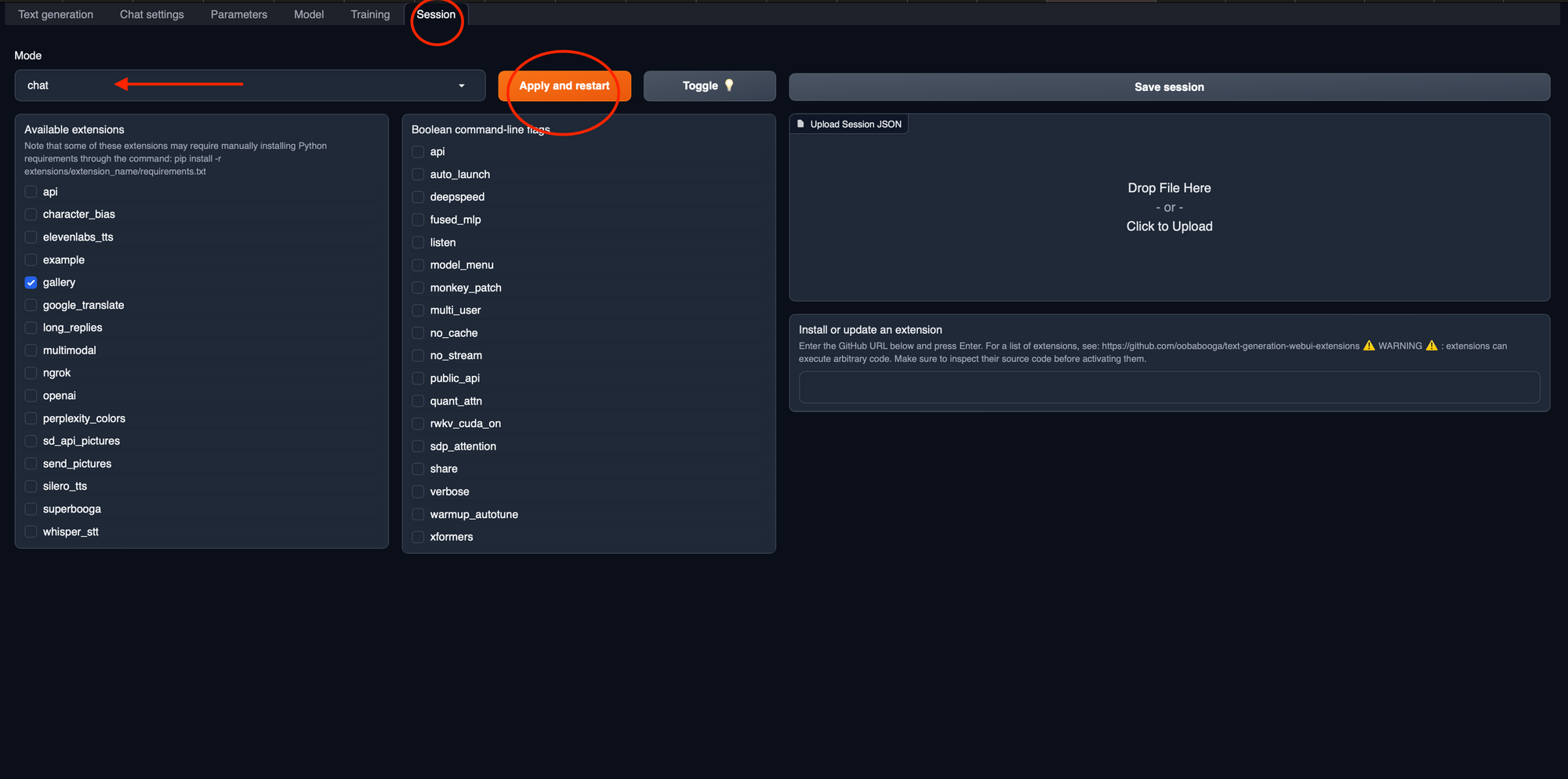
4. Configure the Session: Since we are using a chat model in this example, navigate to the "Session" tab and from the "Mode" dropdown, select "Chat," and then click "Apply and Restart." This will configure the session for a chat interaction.
5. Start Chatting with Llama 2: Finally, head over to the "Text Generation" tab, where you can start conversing with the Llama 2 model. Type your questions, comments, or prompts, and watch as the model responds, all within the comfort of your local machine.
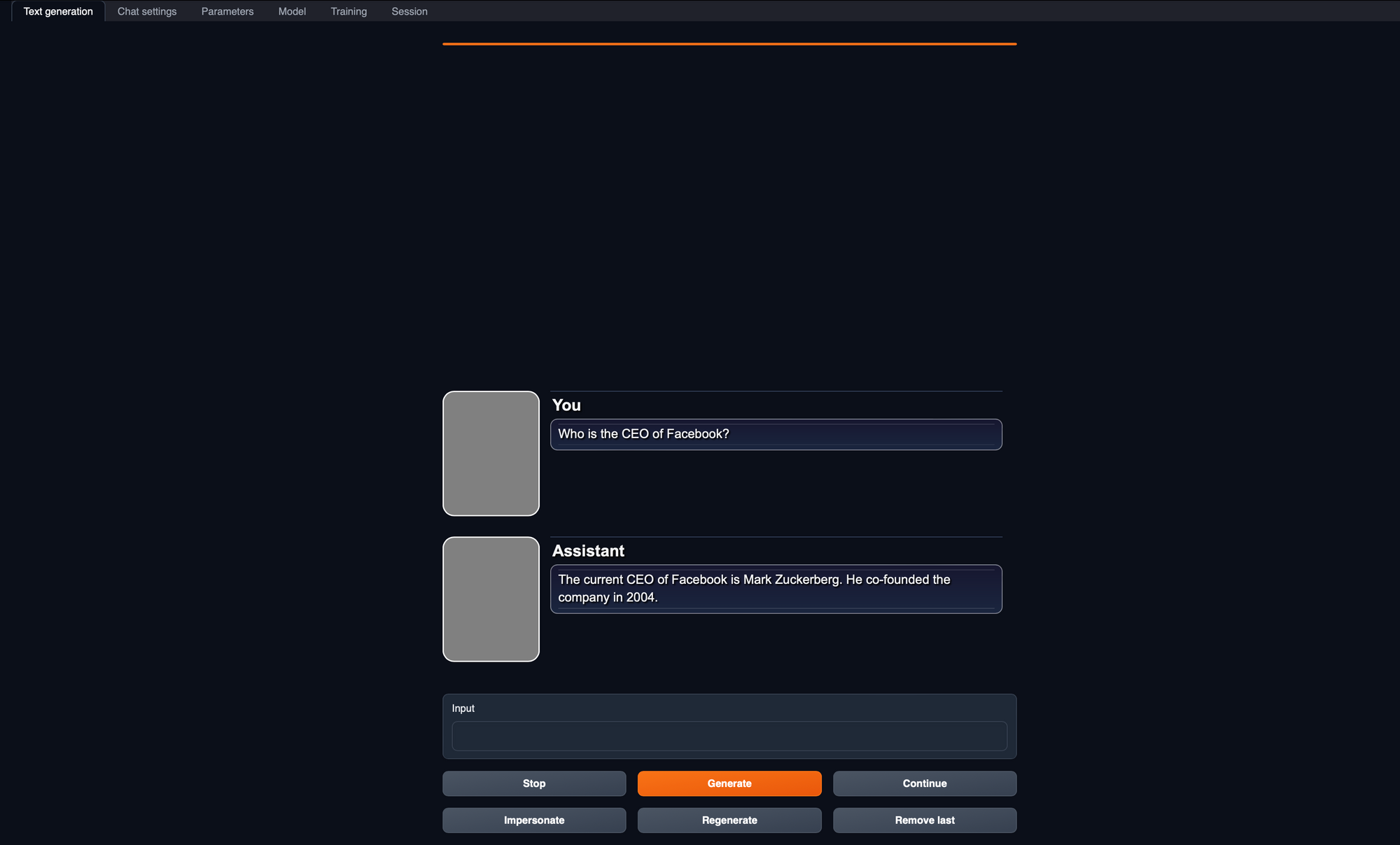
These steps provide a simple and straightforward way to engage with Llama 2 using a convenient web interface. You now have the power of a ChatGPT-like model right at your fingertips, with the flexibility and privacy of running it on your own computer. Enjoy the conversations!
What's Next?
We've just scratched the surface of what's possible with Llama 2. Running it locally is a fantastic starting point, but there are whole new dimensions to explore beyond that.
AI for Everyone
Running Llama 2 locally is about more than playing with cool tech; it's a step towards making AI available to all. Think about what you could create, innovate, or even change with access to this.
Cloud Hosting
Want to go bigger? Consider hosting Llama 2 on the cloud and protecting it with an API. It's not as complex as it sounds, and we'll cover it in another article. The cloud opens up new ways to use the model, from building smart apps to data analysis.
Customizing with Fine-Tuning
Your organization might need something special. That's where fine-tuning comes in. You can tweak Llama 2 to fit exactly what you need. Imagine tailoring Llama 2 to answer customer support inquiries with the specific knowledge of your company's products or translating texts into a local dialect that mainstream translation models don't handle. Fine-tuning allows you to build applications such as:
- Personalized Customer Service: A chatbot that knows your products inside and out, providing instant, detailed support.
- Localized Language Processing: Understanding and communicating in regional languages or dialects that other models overlook.
- Healthcare Assistance: Customized medical inquiries handling, interpreting patient data and assisting healthcare professionals with diagnostic support.
- Educational Support: Creating educational content that's tailored to the specific curriculum or learning level of a school or educational institution.
Stay tuned for a separate post on this where we'll dive into the nuts and bolts of fine-tuning.
Note that there are also other viable techniques to augment LLMs depending on the use-case. I recently published a guide that dives deep into using vector embeddings to augment large language models.
Conclusion
So, here we are at the end of our guide. We've explored how to set up Llama 2, touched on the huge potential of AI, and now it's time to look forward. But you don't have to do this alone.
At Sych, we're all about taking the complexity out of AI. We're excited about what it can do, and we want to help you find out how it can fit into your world, whether you're running a small business or part of a bigger organization. From fine-tuning models to tailor-made solutions, we're here to support you every step of the way.
We don't believe in one-size-fits-all. We'll work with you to figure out what you need, and we'll be there to guide you through the whole process. No jargon, no fuss, just straightforward help to get you where you want to go.
If you want to know more, just reach out. We're here and ready to start when you are. Let's see what we can do together.