How to augment LLMs like ChatGPT with your own data
Learn to augment LLMs like ChatGPT with your own data using Langchain. This guide walks you through some key concepts and building a Q/A app with Python and Streamlit, introducing new possibilities for AI applications.


Introduction
Have you ever wished that the technology around you could understand you just a bit better? Sure, OpenAI's ChatGPT is a marvel at crafting human-like text. It's like having a chat with a well-read friend. But what if this AI friend could also understand the intricate details of your unique world?
Let's take this for a spin. Picture being a biochemist working on a groundbreaking vaccine, or a historian delving into the socio-cultural dynamics of a forgotten era or think of a customer service department aiming to build an intelligent chatbot trained on their own knowledge base, offering highly personalized support. Now, imagine an AI that not only assists you with information but understands your field's complex terminology and the subtle nuances of your work. That’s the level-up we're talking about!
That's where augmenting LLMs like ChatGPT with private data comes into play. It's about equipping AI with the contextual knowledge that makes it not just intelligent, but relevant and intuitive.
In this article, we'll be exploring how to make this exciting possibility a reality. We'll touch upon the architectural concepts that allow us to merge private data with a large language model like ChatGPT. And, we're not stopping at theory. We'll roll up our sleeves and build a Q/A web application to demonstrate how this augmentation can be put to use.
So, are you ready to dive in and see how we can transform AI from a useful tool to a personalized aide? Let's get started.
Charting Our Course: How We'll Bring Augmentation to Life
With our eyes set on the goal of creating a more personalized AI experience, we need a game plan that's smart and feasible. Fine-tuning a large language model, while a possible route, can be a hefty and expensive endeavor. Therefore, we are going to adopt a different, more cost-effective strategy.
In essence, we'll keep our knowledge source—private data—separate from the language model. This approach gives us flexibility and keeps our LLM, ChatGPT, from being bogged down with a huge load of data to process.
The process is fairly straightforward. When a user poses a question, our system kicks into action, diving into the private data to fish out the most relevant information. This data is then refined into a concise prompt that ChatGPT can comprehend and respond to.
This way, we not only maintain the efficiency of the LLM but also provide the user with a response that's informed by their private data. And in cases where the data doesn't hold the answer, the user is promptly informed about the lack of relevant information.
By adopting this method, we can smartly integrate private data into our AI system, creating a ChatGPT that's tailored to the user's world. Now, that's what we call a win-win situation.
The Technical Blueprint: Bringing Augmentation to Life
Before we delve into the nitty-gritty, let's get an overview. Here's an architectural diagram to help you visualize the process:
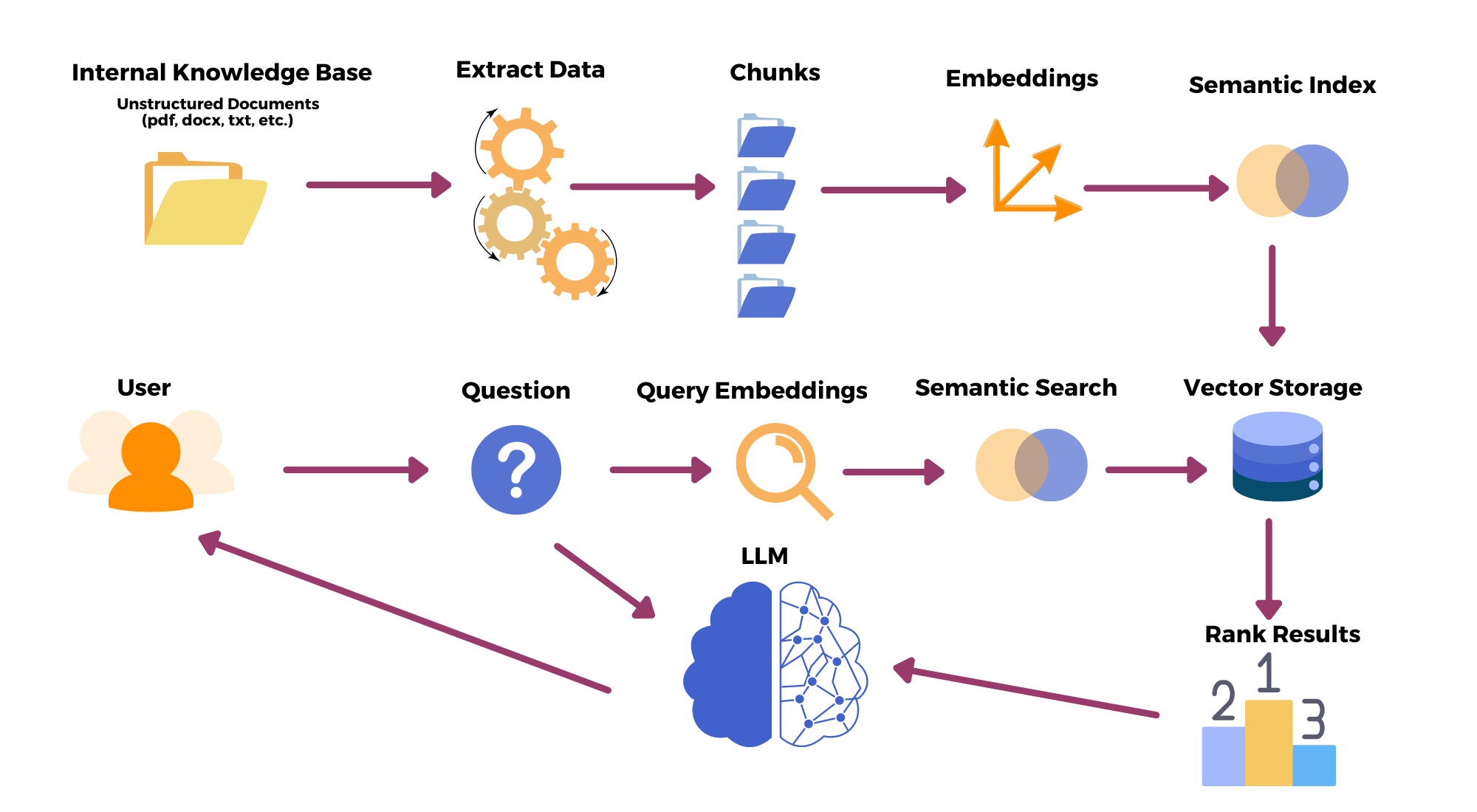
Let's break it down:
- Data Extraction: Our journey begins with raw data, which could come in various forms such as files, PDFs, or even handwritten notes. The first task at hand is to extract this data, turning a mixed bag of information into a structured format that we can work with.
- Chunking: Given that language models like ChatGPT have a token limit when answering a prompt, it's essential to split our data into manageable 'chunks'. By doing so, we ensure that our model can process the information efficiently.
- Embeddings: Next, we compute 'embeddings' for each chunk. But what exactly are embeddings? In simple terms, they are a way of converting text data into numerical vectors. This mathematical transformation allows us to capture the semantics and context of the data in a format that's more digestible for our model.
- Vector Database: With our embeddings in hand, we then load them into a vector database. This step allows us to query the embeddings when a user poses a question. Think of it as a digital library where each book (embedding) is indexed for quick and efficient retrieval.
- User Query and Response: Now we come to the crux of the process. When a user asks a question, we perform a search on our vector database to find the most relevant chunk (or 'book' in our library analogy). We then prepare a prompt based on the user's query and the data matched from the database. This prompt is then fed into the LLM.
- Answer Generation: Our tailored prompt makes its way to LLM, which processes it and generates a response. It's crucial to ensure that our prompt is concise and clear to avoid any hallucinations or incorrect information.
And voila! The user receives an informed, personalized response based on their private data. In case the system doesn't find any relevant information in the database, it lets the user know about this.
So, there you have it: the behind-the-scenes tour of how we can augment a large language model with private data. Up next, we'll bring these steps to life as we code our Q/A web application. Stay tuned!
Building the Q/A Web App
Let's get our hands dirty with the implementation, shall we? We'll be juggling primarily with Python here. Why Python? Well, its simplicity and the fact that it's beloved by the data science community makes it a choice too good to ignore. This nifty application we're about to craft will be constructed with a couple of powerful tools. The backend? We've got the mighty Langchain API, a game-changer when it comes to handling large language models. Our frontend? Enter Streamlit, an open-source app framework which lets us create interactive web applications for machine learning with pure Python. The recipe sounds promising, doesn't it?
But hold your horses! Before we delve into the meat of the code, let me share the link to the full source code on GitHub.
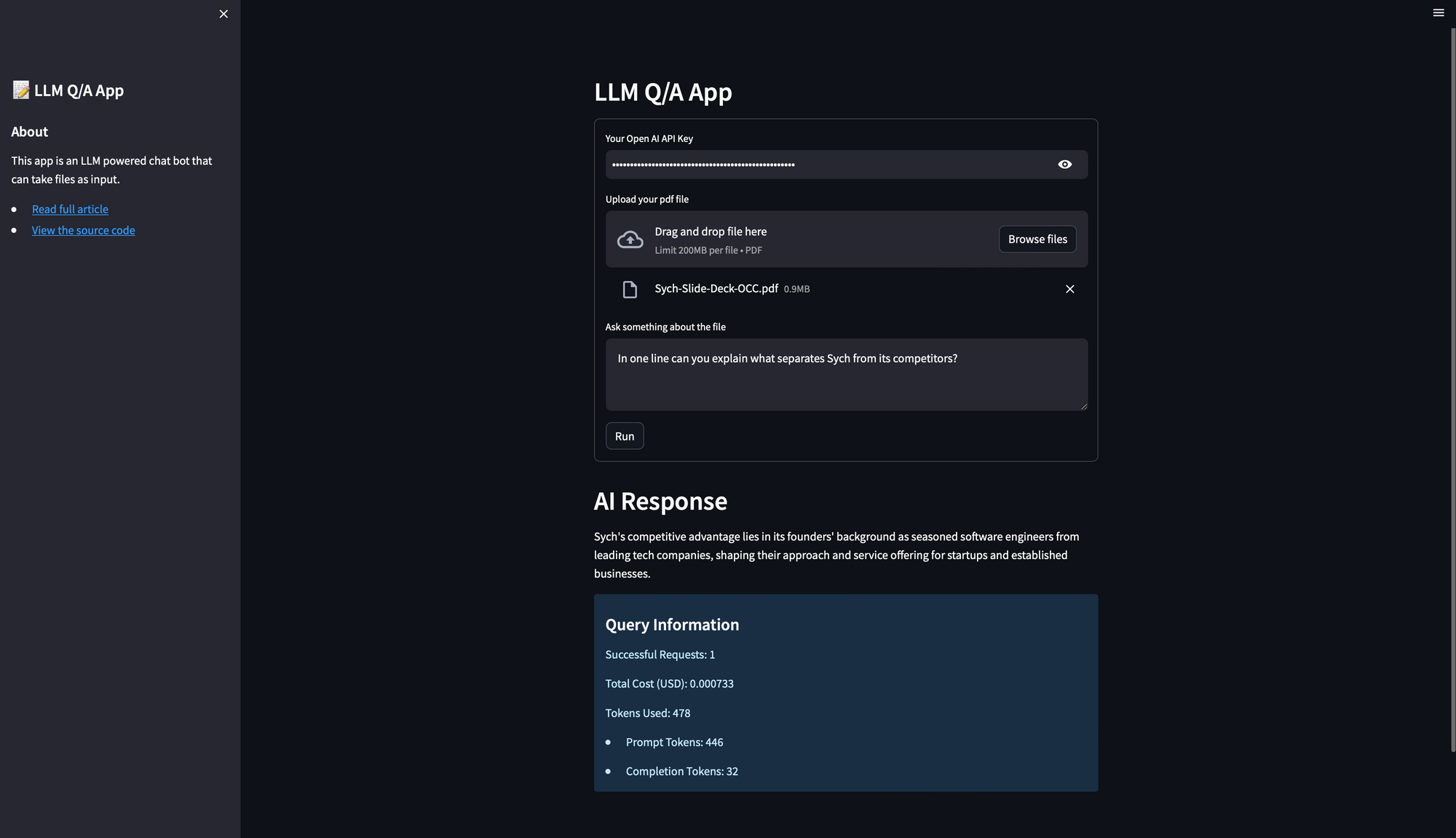
The image above gives you a sneak peek into how the final application looks. The user needs to input the OpenAI API Key, upload a pdf file, and ask a question. The user then gets an answer based on data from the uploaded file along with some metadata about the total cost (USD) of the query, and details about the tokens used. As you can see, it's a fairly straightforward interface with input fields and a submit button. And yet, beneath this simplicity lies the power of language models and the beauty of seamless interaction between frontend and backend.
Now, a quick disclaimer before we proceed: the code we're going to discuss here is not production-ready. It's a proof of concept, a playground to understand and implement the concepts we've been discussing so far. That said, there's plenty of room for improvement and optimization. Feel free to get your hands on the code, tinker around, add more features, optimize it, make it your own. After all, that's what learning and coding is all about, right? So, let's dive in and start piecing together the blocks of our Q/A web application!
Pre-requisites
Before we delve into code, there are certain pre-requisites that are essential:
- OpenAI API Key: You need to have an OpenAI API key to use the ChatGPT LLM used by this guide. You can skip this step, if you want to use any other LLM of your choice. You can get the OpenAI API key by registering on the OpenAI website and following their instructions.
- Knowledge of Langchain Concepts: This guide assumes that you have a basic understanding of Langchain and its concepts. You will need this to understand how we're going to augment the LLM with our own data. If you are new to Langchain, it is recommended to go through the Langchain documentation to familiarize yourself with its concepts.
- Knowledge of Streamlit: Streamlit is a Python library that allows you to quickly create interactive web applications. We'll be using Streamlit for our frontend. You should have a basic understanding of how to use Streamlit. If you're not familiar with it, you can check out the Streamlit documentation for a quick start.
Setting up the Development Environment
Before we dive into coding, it's crucial to set up a proper development environment. To isolate our project from the rest of your system and to avoid potential conflicts with other Python libraries, we'll use a virtual environment.
In a new directory, you can create a new virtual environment using Python's built-in venv module:
python3 -m venv llm_qa_app_venvTo activate this environment, you can use the following command:
- On Linux or MacOS:
source llm_qa_app_venv/bin/activate- On Windows:
.\llm_qa_app_venv\Scripts\activateInstall Necessary Python Libraries
For our application, we need several Python libraries. Let's install them using pip, the Python package manager, while the virtual environment is active:
pip3 install streamlit PyPDF2 langchain faiss-cpu openai tiktokenThis command installs all necessary libraries and their dependencies in one go. Here's a brief explanation of why we need each of these libraries:
streamlit- This is our tool for building the web interface of our application. Streamlit is an open-source library that allows us to rapidly build and deploy web applications, and it's particularly well-suited to data-focused Python applications.PyPDF2- We use this library for handling PDF files. PyPDF2 allows us to read PDF files and extract text from them, which is essential for our application as it processes user-uploaded PDFs.langchain- This library provides us with tools for working with large language models. Langchain simplifies the process of integrating LLMs into our application, and it provides easy-to-use APIs for tasks such as splitting text and finding similar pieces of text.faiss-cpu- FAISS (Facebook AI Similarity Search) is a library developed by Facebook Research for efficient similarity search and clustering of high-dimensional vectors. We use it in our application to store and query embeddings of the text chunks from the uploaded documents. It's a crucial part of our approach as it enables us to find the most relevant text chunks to a given query.openai- OpenAI’s Python library, we'll use this to generate embeddings for our chunks of text and to interface with the language model.tiktoken- A Python library from OpenAI. We'll use this to count how many tokens are in a text string without making an API call.
With all these libraries installed, you're all set to start writing the Python code for the application.
Building the Frontend with Streamlit
The first part of our code is all about setting up the user interface. We use the Streamlit library for this purpose. Streamlit is an excellent choice for building data applications quickly with Python.
First, we create a new app.py file and we import the Streamlit library, which we'll use for our web app.
import streamlit as st
We create a sidebar with some information about the app using st.sidebar. Inside this block, we can put anything we want to be shown in the sidebar. Here, we use st.title to add a title to our sidebar, and st.markdown to add some information about the app.
with st.sidebar:
st.title("📝 LLM Q/A App")
st.markdown('''
## About
This app is an LLM powered chat bot that can take files as input.
- [Read full article](https://sych.io/blog/how-to-augment-chatgpt-with-your-own-data)
- [View the source code](https://github.com/sychhq/sych-blog-llm-qa-app)
''')
Next, we define a function main() that contains the core functionality of our app. We use st.header to add a title to the main page.
def main():
st.header("LLM Q/A App")
We create a form that the user can interact with. st.form creates a new form, form.text_input creates a text input field for the user's OpenAI API Key, form.file_uploader creates a file upload button for the user to upload a PDF, and form.text_area creates a text area for the user to type their question.
form = st.form(key='my_form')
form.text_input("Your Open AI API Key", key="open_ai_api_key", type="password")
uploaded_pdf = form.file_uploader("Upload your pdf file", type=("pdf"))
query = form.text_area(
"Ask something about the file",
placeholder="Can you give me a short summary?",
key="question"
)
form.form_submit_button("Run")
Finally, we ensure that the main() function is only called when the script is run directly, not when imported as a module.
if __name__ == '__main__':
main()
To view your Streamlit frontend, run the following command:
streamlit run app.pyYou should be able to view your app on the browser at http://localhost:8501
Building the Backend with Langchain
The second part of our code focuses on the core logic that processes user inputs and interacts with the large language model (LLM) through the Langchain library.
Import Necessary Libraries and API
We first import all the necessary packages for our backend operations.
from PyPDF2 import PdfReader
import pickle
import os
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.chains.question_answering import load_qa_chain
from langchain.callbacks import get_openai_callback
Define submit Function
This function will be called when the user submits a question. Here we will read the uploaded PDF, split it into chunks, compute their embeddings, and save them to a FAISS vector store. We will also handle the user's query here.
def submit (uploaded_pdf, query, api_key):
Note that we also need to pass the submit function to the form's submit button, we added in the previous section, as a callback.
form.form_submit_button("Run", on_click=submit(uploaded_pdf=uploaded_pdf, query=query, api_key=st.session_state.open_ai_api_key))PDF Text Extraction
The first step in the submit function is to extract text from the uploaded PDF. We'll use the PyPDF2 library for this. We initialize a PdfReader with the uploaded PDF and then iteratively extract text from every page of the PDF.
if uploaded_pdf:
pdf_reader = PdfReader(uploaded_pdf)
text = ""
for page in pdf_reader.pages:
text += page.extract_text()
Text Splitting
With the text extracted, we need to split it into manageable chunks. For this, we're going to use the RecursiveCharacterTextSplitter from the langchain API.
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len
)
chunks = text_splitter.split_text(text=text)
The chunk_size and chunk_overlap parameters are configurable according to your needs.
Compute Embeddings and Vector Store
The next step is to compute the embeddings of our chunks and create a vector store for them. To reiterate, embeddings are vector representations of our text that can be used to compute semantic similarity. We will be using OpenAIEmbeddings for this and storing the embeddings using FAISS.
store_name = uploaded_pdf.name[:4]
if os.path.exists(f"{store_name}.pkl"):
with open(f"{store_name}.pkl", "rb") as f:
vector_store = pickle.load(f)
else:
embeddings = OpenAIEmbeddings(openai_api_key=api_key)
vector_store = FAISS.from_texts(chunks, embedding=embeddings)
with open(f"{store_name}.pkl", "wb") as f:
pickle.dump(vector_store, f)The vector store is then serialized to a file for later use. If the vector store already exists (i.e., if we've processed this PDF before), we simply load it from the file.
Accept User Queries
Once the user submits a query, we need to fetch the most relevant chunks of text from our vector store.
if query:
docs = vector_store.similarity_search(query=query, k=2)
The similarity_search function of the FAISS vector store helps us fetch the top 'k' similar chunks. You can adjust the 'k' parameter as per your requirement.
Generate Responses using LLM
To generate a response to the user query, we'll use the ChatOpenAI model provided by the langchain API.
llm = ChatOpenAI(openai_api_key=api_key, temperature=0.9, verbose=True)
chain = load_qa_chain(llm=llm, chain_type="stuff")We use ChatOpenAI as our language model and load a question-answering chain. The temperature parameter here influences the randomness of the output. You can adjust it according to your preference.
Callbacks and Query Information
with get_openai_callback() as cb:
response = chain.run(input_documents=docs, question=query)
st.header("AI Response")
st.write(response)
st.info(f'''
#### Query Information
Successful Requests: {cb.successful_requests}\n
Total Cost (USD): {cb.total_cost}\n
Tokens Used: {cb.total_tokens}\n
- Prompt Tokens: {cb.prompt_tokens}\n
- Completion Tokens: {cb.completion_tokens}\n
''')We run our question-answering chain with the relevant documents and query and display the response. We also provide additional information about the request, such as the cost and token usage.
And with that, we have added the necessary backend logic to our frontend code.
Here is what the final app.py should look like:
import streamlit as st
from PyPDF2 import PdfReader
import pickle
import os
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.chains.question_answering import load_qa_chain
from langchain.callbacks import get_openai_callback
with st.sidebar:
st.title("📝 LLM Q/A App")
st.markdown('''
## About
This app is an LLM powered chat bot that can take files as input.
- [Read full article](https://sych.io/blog/how-to-augment-chatgpt-with-your-own-data)
- [View the source code](https://github.com/sychhq/sych-blog-llm-qa-app)
''')
def submit (uploaded_pdf, query, api_key):
if uploaded_pdf:
#Pdf Text Extraction
pdf_reader = PdfReader(uploaded_pdf)
text = ""
for page in pdf_reader.pages:
text += page.extract_text()
#Text Splittting
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len
)
chunks = text_splitter.split_text(text=text)
#Compute Embeddings and Vector Store
store_name = uploaded_pdf.name[:4]
if os.path.exists(f"{store_name}.pkl"):
with open(f"{store_name}.pkl", "rb") as f:
vector_store = pickle.load(f)
else:
embeddings = OpenAIEmbeddings(openai_api_key=api_key)
vector_store = FAISS.from_texts(chunks, embedding=embeddings)
with open(f"{store_name}.pkl", "wb") as f:
pickle.dump(vector_store, f)
if query:
#Accept User Queries
docs = vector_store.similarity_search(query=query, k=2)
#Generate Responses Using LLM
llm = ChatOpenAI(openai_api_key=api_key, temperature=0.9, verbose=True)
chain = load_qa_chain(llm=llm, chain_type="stuff")
#Callback and Query Information
with get_openai_callback() as cb:
response = chain.run(input_documents=docs, question=query)
st.header("AI Response")
st.write(response)
st.info(f'''
#### Query Information
Successful Requests: {cb.successful_requests}\n
Total Cost (USD): {cb.total_cost}\n
Tokens Used: {cb.total_tokens}\n
- Prompt Tokens: {cb.prompt_tokens}\n
- Completion Tokens: {cb.completion_tokens}\n
''')
def main():
st.header("LLM Q/A App")
form = st.form(key='my_form')
form.text_input("Your Open AI API Key", key="open_ai_api_key", type="password")
uploaded_pdf = form.file_uploader("Upload your pdf file", type=("pdf"))
query = form.text_area(
"Ask something about the file",
placeholder="Can you give me a short summary?",
key="question"
)
form.form_submit_button("Run", on_click=submit(uploaded_pdf=uploaded_pdf, query=query, api_key=st.session_state.open_ai_api_key))
if __name__ == '__main__':
main()What's next?
The application we've just developed is a relatively basic one, but it serves as a potent proof of concept for the numerous groundbreaking potential use cases that arise from augmenting large language models with private data. This method has the potential to drastically transform how we use and interact with AI models by making them significantly more personalized and context-aware.
- Industry-Specific Language Understanding: Each industry has its own set of terminologies and jargon. By using this method, you could train an AI to comprehend the specific language nuances of different industries. This could be particularly useful in fields like law or medicine, where specific terminologies are commonly used.
- Customer Support: By augmenting LLMs with information about a company's products, services, policies, etc., AI can provide highly accurate and personalized customer support. This could significantly reduce the workload of customer support teams and improve the customer experience.
- Internal Business Operations: For businesses with large amounts of internal documents and knowledge, this approach could assist in automating responses to common queries. This could range from answering questions about company policy to providing specific technical assistance.
- Education and Training: This approach could be used to personalize educational content, providing students with an AI tutor that has been specifically tailored to their syllabus and learning materials. It could also be used in corporate training, giving employees access to an AI that understands their specific training materials and company protocols.
- Privacy-Preserving Data Utilization: The most compelling aspect of this approach is that it enables the usage of private data for model training and interaction, without directly exposing the data. This could open new avenues for utilizing sensitive data while preserving privacy.
While this application is just a starting point, the real potential lies in developing more complex applications tailored to specific needs.
Conclusion
We're standing at a compelling juncture in the evolution of AI. The melding of Large Language Models like ChatGPT with custom, private data opens the door to a realm of bespoke applications limited only by our imagination. From creating nuanced AI systems for specific industries to delivering hyper-personalized customer experiences and preserving privacy in an increasingly data-driven world, the possibilities are endless.
Our exploration in this article with a simple Q/A app is just the tip of the iceberg. It serves as a springboard to dive deeper, to innovate, and to create AI applications that are more intuitive, more personalized, and ultimately, more valuable.
At Sych, we believe in the transformative potential of these advancements. As you ponder the application of this technology in your own field, consider how a customized AI solution could propel your operations forward. We're here to help translate this potential into reality. Our team of AI experts specializes in developing tailored AI solutions that fit seamlessly into your operations, providing your business with the AI-powered edge it needs to excel in today's competitive landscape.
To learn more about how Sych can support your organization in leveraging the next wave of AI technology, please contact us. We're excited to work together, pushing the boundaries of what's possible with AI, and shaping the future, one line of code at a time.
Thank you for reading, and we look forward to pioneering the AI frontier together!