How to Deploy Large Language Models like Llama 2 on the Cloud in Minutes with Sych LLM Playground
Deploy LLMs like Llama 2 on the cloud effortlessly with Sych LLM Playground. Whether you're a hobbyist or a data scientist, this open-source tool simplifies deployment to providers like AWS, making cutting-edge AI accessible.


Introduction
Llama 2 is making waves in the world of AI. With up to a whopping 70B parameters and a 4k token context length, it represents a significant step forward in large language models. It's open-source, free for both research and commercial use, and provides unprecedented accessibility to cutting-edge AI technology. But what if you want to take it a step further and deploy your very own Llama 2 on the cloud?
The thought of deploying such a complex model on the cloud can be intimidating. From understanding cloud infrastructure to dealing with hardware configurations and setting up HTTP APIs, it's a process filled with technical challenges.
That's exactly why, in this guide, we're going to introduce you to sych-llm-playground, a free open-source tool our team released recently. Whether you're a hobbyist, an indie hacker, or a seasoned data scientist, this tool is designed to take the complexity out of deploying language models like Llama 2 on the cloud. Simple commands, clear instructions, and no need to sweat the cloud-related stuff.
Ready to explore Llama 2 on the cloud without the hassle? Let's dive in!
Overview of Sych LLM Playground
It is an interactive CLI tool that our team developed to help people deploy and interact with large language models like Llama 2 on the cloud. Working on various LLM projects for clients, we recognized that not everyone has the time or expertise to deal with the complexities of cloud deployment.
This simple tool is still in its alpha stage and was originally conceived during an internal hackathon at Sych. We recognized the value in making the deployment and management of large language models like Llama 2 more accessible on the cloud. Believing that this tool could be of great benefit to the broader community and has scope of improvement, we decided to make it open-source.
Note: At the time of writing, the latest version of sych-llm-playground is v0.3.0. New features could be added, so the instructions in this post might get outdated. It's always recommended to read the full documentation to stay up to date with the latest information.
Prerequisites
Before we get started with sych-llm-playground, there are a few requirements you'll need to meet:
- Python Version: 3.10 or higher.
- A Cloud Account: At the time of writing,
sych-llm-playgroundonly supports AWS, but we're planning to add more cloud providers soon.
Setting up AWS
Even with this tool, you will need to setup permissions and roles on AWS to allow sych-llm-playground to access and automate things for you.
Register for an AWS Account:
If you don't have one already, you can create an AWS account here.
Create an IAM Role for SageMaker and API Gateway:
- Create a New IAM Role: Navigate to IAM in the AWS Console, and create a new role.
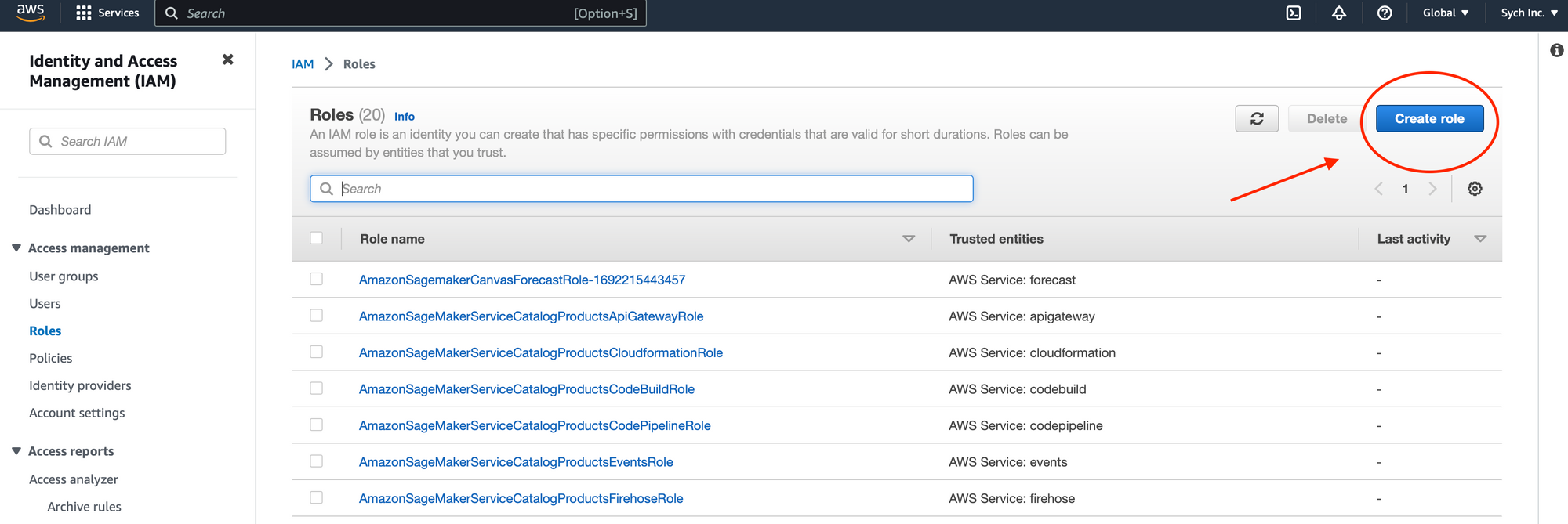
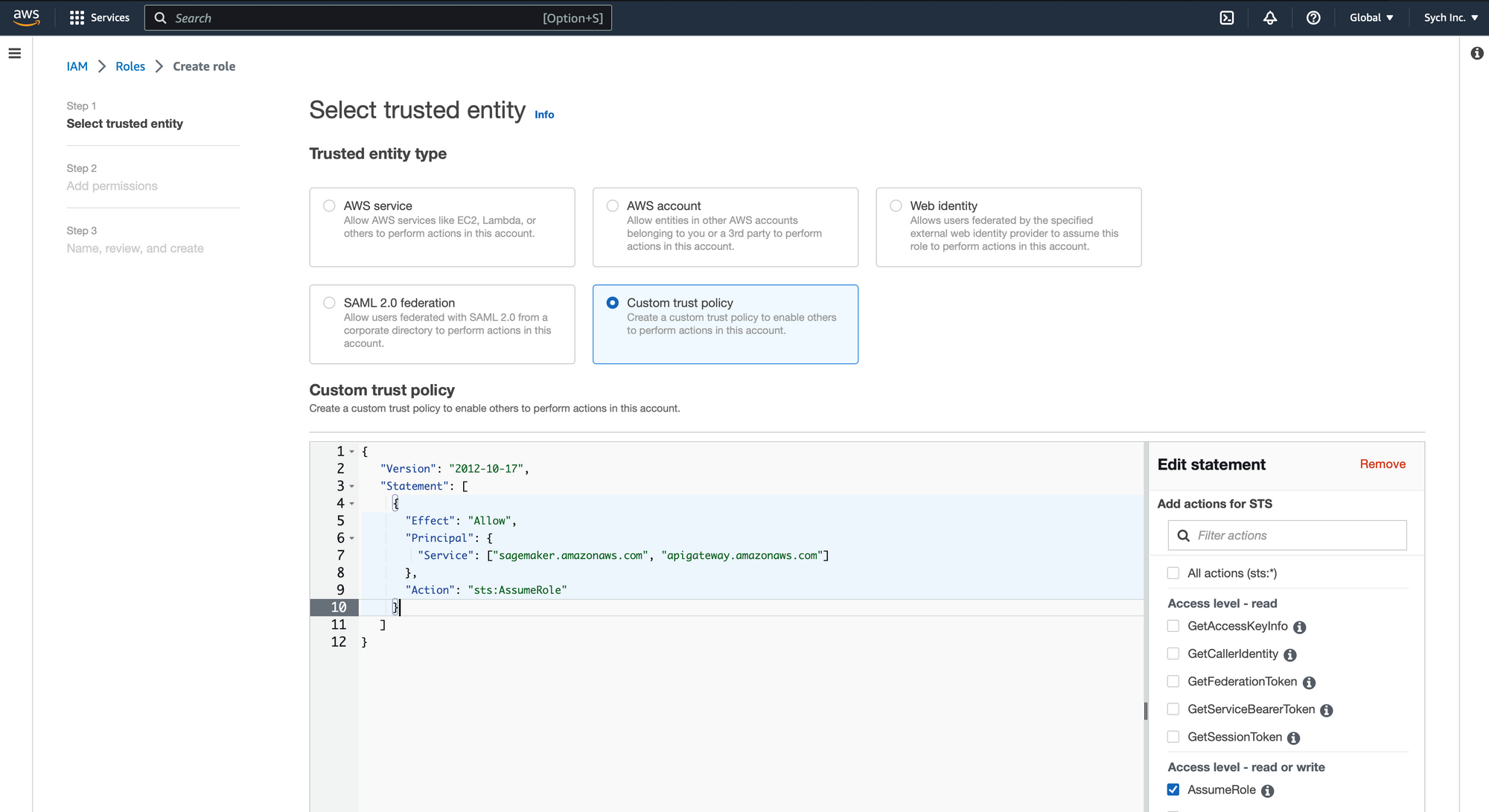
- Add Trust Policy: Use the following custom trust policy to allow AWS SageMaker and AWS API Gateway to assume this role:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": ["sagemaker.amazonaws.com", "apigateway.amazonaws.com"]
},
"Action": "sts:AssumeRole"
}
]
}
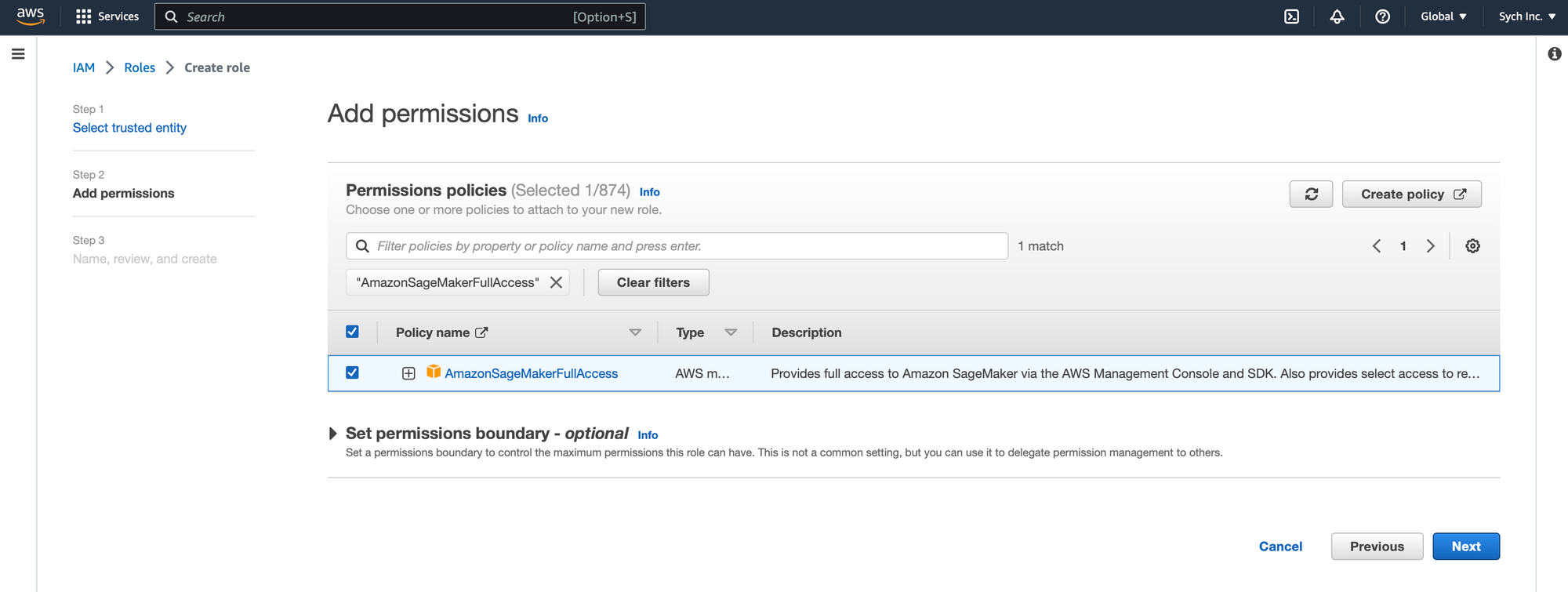
- Attach Permission Policy: Under the newly created role, attach the
AmazonSageMakerFullAccessmanaged policy.
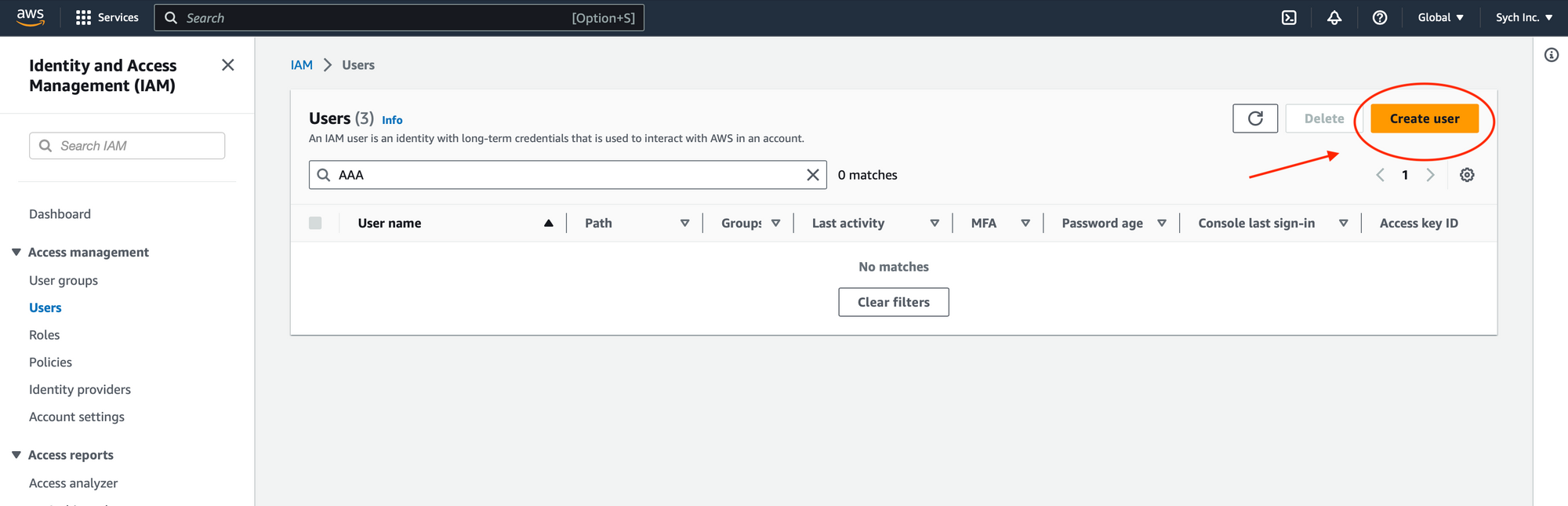
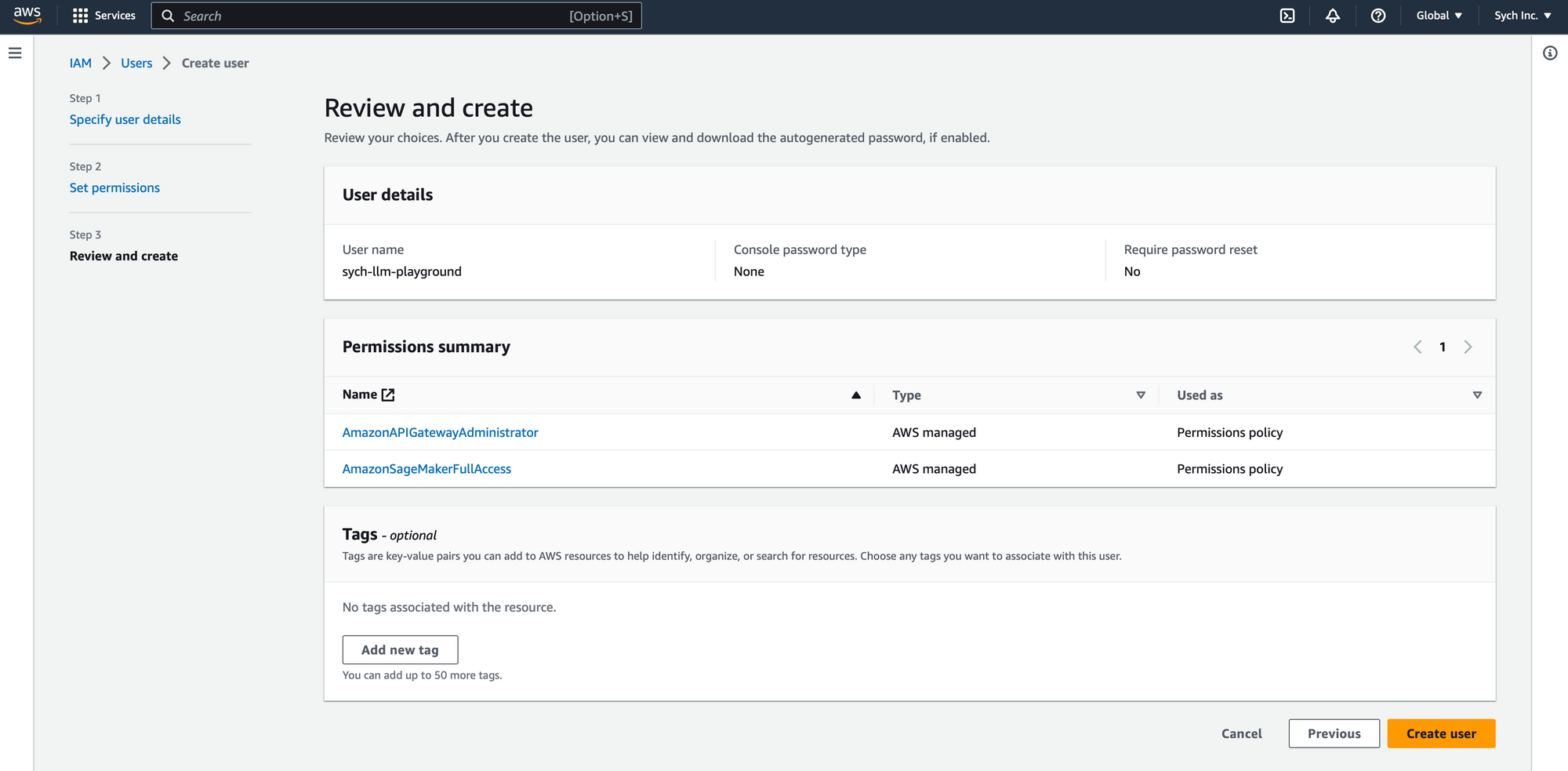
Create an IAM User with Necessary Permissions:
- Create IAM User: In the IAM section of the AWS Console, create a new user.
- Attach Managed Policies: Attach the
AmazonSageMakerFullAccessandAmazonAPIGatewayAdministratormanaged policies to the user.
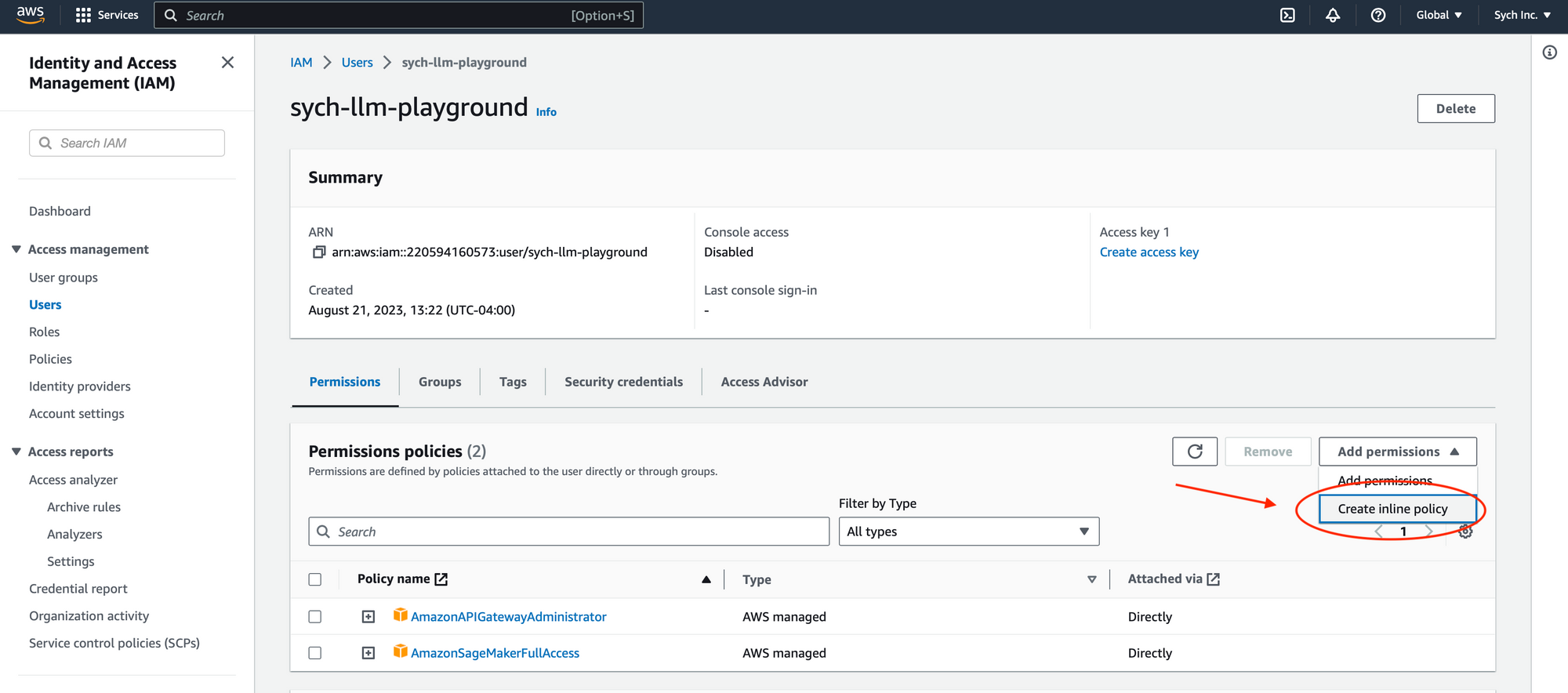
- Add Custom Inline Policy: Add the following custom inline policy, replacing
YOUR_IAM_ROLE_ARNwith the ARN of the IAM role you created above:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "YOUR_IAM_ROLE_ARN"
}
]
}
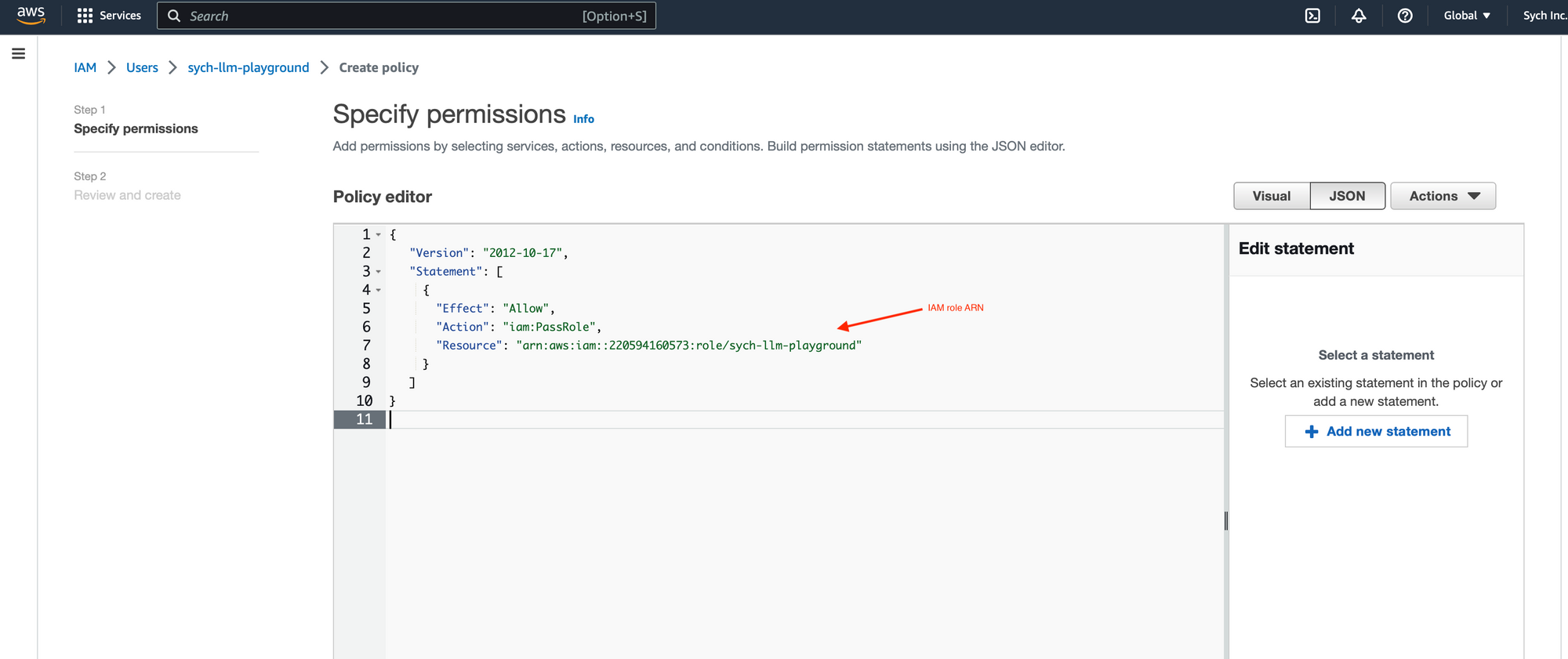
Create an Access Key
In the user's security credentials tab, create a new access key. Be sure to store the generated Access Key ID and Secret Access Key in a safe place.
These are the prerequisites needed to proceed with the installation and usage of sych-llm-playground. Make sure you've gone through all the steps, and you'll be ready to move on!
Installing Sych LLM Playground
Once you've got the prerequisites in place, installing sych-llm-playground is a simple process.
Open the command line or terminal on your machine and install the package using pip by running:
pip install sych-llm-playgroundYou can verify the installation by running:
sych-llm-playground --versionYou should see the version number printed in the terminal, confirming that sych-llm-playground has been successfully installed.
Configuring the CLI
After installing the package, the next step is to configure sych-llm-playground with your cloud provider details. As of now, the tool supports AWS, so you'll need to provide the necessary credentials you created in the previous section including your IAM user's Access Key, Secret Key and your IAM role's ARN. You'll also be asked about the AWS region you want to deploy in which is set to us-west-2 by default.
Here's how you'll configure the CLI:
> sych-llm-playground configure
******
******* ******
******* *******
****, ***** *****
*** ************** *** @@@@@@@@@ @@@
*** *** **** *** @@@ @@@ @@@ @@@@@@@ @@@@@@@@
*** *** **** *** @@@@@@@@ @@@ @@@ @@@ @@@ @@@
** ***** ***** *** @& @@@ @@@@@ @@@ @@@ @@@
************** *** @@@@@@@ @@@ @@@@@@ @@@ @@@
******* ******* @@@
******* ******
**********
**
Welcome to the Sych LLM Playground CLI.
This tool is part of our efforts to contribute to the open-source community.
Explore more at https://sych.io
For detailed documentation, visit https://sych-llm-playground.readthedocs.io
Let's begin with the configuration.
[?] Please choose a provider:: AWS
> AWS
Please Provide your AWS Access Key: xxxxxxxx
Please provide your AWS Secret Key: xxxxx
Please provide your ARN of the IAM role for SageMaker: xxxxxx
Please provide the AWS Region you want to deploy in [us-west-2]:
Configuration successful!Deploy A Model
Deploying a model to the cloud is a simple process with sych-llm-playground. By running the deploy command, you can select your cloud provider, in this case, AWS, and choose the model you'd like to deploy. In this example, we're going to deploy Llama-2-7b-chat, which is more suited for chat interactions. The tool manages all the necessary configurations and setups for you. Once the deployment is complete, you'll also receive public http url that you can use to interact with the model outside of this CLI.
The deployment might take a while so be patient :)
> sych-llm-playground deploy
[?] Please choose a provider:: AWS
> AWS
✓ Cloud Credentials validated.
✓ Cloud Credentials loaded.
[?] Select a model id to deploy:: Llama-2-7b-chat - v1.1.0
Llama-2-7b - v2.0.0
> Llama-2-7b-chat - v1.1.0
Llama-2-13b - v2.0.0
Llama-2-13b-chat - v1.1.0
Llama-2-70b - v1.1.0
Llama-2-70b-chat v1.1.0
Deploying... Why not grab a cup of coffee? /|\
✓ Model and Endpoint Deployed
Endpoint name: sych-llm-pg-meta-textgeneration-llama-2-7b-f-e-1692399247
✓ Created REST API
✓ Fetched REST API
✓ Created API resources
✓ Created a POST method
✓ Created API Integration with SageMaker endpoint
✓ API Deployed
Public API HTTP (POST) URL: https://dhdb1mu9w1.execute-api.us-west-2.amazonaws.com/prod/predict
Deployment successful!Note on Quotas and Instance Types
If you encounter an error related to unassigned quotas for specific instance types on AWS when deploying a model, you can apply for the required quota for the instance type mentioned in the error message. Simply go to your AWS Console -> Service Quotas -> Apply Quotas for specific instance types.
For more details and guidance on this process, including associated costs, please refer to the documentation.
List Deployed Resources
Let's take a look at what's been deployed so far. The sych-llm-playground tool provides a straightforward way to list all your deployed resources, giving you a clear snapshot of your environment.
By executing the list command, you'll get a detailed overview of what's currently deployed on your cloud provider. In this case, with AWS, the command will provide details like this:
> sych-llm-playground list
[?] Please choose a provider:: AWS
> AWS
✓ Cloud Credentials validated.
✓ Cloud Credentials loaded.
Deployed Models:
{'name': 'sych-llm-pg-meta-textgeneration-llama-2-7b-f-m-1692586488'}
Deployed Endpoints:
{'name': 'sych-llm-pg-meta-textgeneration-llama-2-7b-f-e-1692586488', 'url': 'https://runtime.sagemaker.us-west-2.amazonaws.com/endpoints/sych-llm-pg-meta-textgeneration-llama-2-7b-f-e-1692586488/invocations'}
Deployed API Gateways:
{'name': 'sych-llm-pg-api-sych-llm-pg-meta-textgeneration-llama-2-7b-f-e-1692558825', 'id': 'dhdb1mu9w1', 'method': 'POST', 'url': 'https://dhdb1mu9w1.execute-api.us-west-2.amazonaws.com/prod/predict'}
From the output, we can see that a model, an endpoint, and an API Gateway have been deployed:
- Model: The trained machine learning model, Llama-2-7b-chat, ready for predictions.
- Endpoint: The hosted deployment of the model, enabling real-time interactions.
- API Gateway: A public gateway to call your endpoints, providing an HTTP URL for interaction.
Together, these components create a streamlined path to deploy and interact with your Llama-2 model on AWS, making the process accessible and manageable.
Interact with the Model
Interacting with the deployed model is a seamless experience using sych-llm-playground. You can engage in a conversation with the model directly through the CLI, setting specific system instructions to guide the model's behavior, or adjusting specific parameters for a model. Such as max new tokens, top_p, and temperature in the case of Llama 2.
You can initiate a chat session by simply running the interact command. You can even specify the model's behavior, like instructing it to be professional, as shown in the following example:
> sych-llm-playground interact
[?] Please choose a provider:: AWS
> AWS
✓ Cloud Credentials validated.
✓ Cloud Credentials loaded.
[?] Select an endpoint to interact with:: sych-llm-pg-meta-textgeneration-llama-2-7b-f-e-1692383398
> sych-llm-pg-meta-textgeneration-llama-2-7b-f-e-1692383398
Provide a system instruction to guide the model's behavior (optional, e.g., 'Please talk in riddles.'): Be professional
Your desired Max new tokens? (default 256): 70
Your desired top_p? (default 0.9):
Your desired Temperature? (default 0.6) :
Type 'exit' to end the chat.
You: Hi my name is Abdullah
Model: Hello Abdullah,
It's a pleasure to meet you. How are you today?
You: What is my name?
Model: Abdullah, it's nice to meet you. How are you today?
You: exit
Exiting chat...
Chat ended.Additionally, if you prefer to interact with the model via the public HTTP url, you can do so with a simple curl command, like so:
curl -X POST \
-H 'Content-Type: application/json' \
-H 'custom_attributes: accept_eula=true' \
-d '{"inputs": [[{"role": "system", "content": "Talk profession"}, {"role": "user", "content": "Hi my name is Abdullah"}]], "parameters": {"max_new_tokens": 256, "top_p": 0.9, "temperature": 0.6}}' \
'https://valauuhvic.execute-api.us-west-2.amazonaws.com/prod/predict'
[
{
"generation":{
"role":"assistant",
"content":" Hello Abdulla, it's a pleasure to meet you. How may I assist you today? Is there something specific you need help with or would you like to discuss a particular topic? I'm here to listen and provide guidance to the best of my abilities. Please feel free to ask me anything."
}
}
]%
Clean up Deployed Resources
The cleanup command in sych-llm-playground ensures that you can safely remove deployed models, endpoints, and API Gateways. This is essential for managing costs and maintaining a clean environment, especially if you have multiple deployments that are no longer needed.
> sych-llm-playground cleanup
[?] Please choose a provider:: AWS
> AWS
✓ Cloud Credentials validated.
✓ Cloud Credentials loaded.
[?] What would you like to cleanup?: Endpoint
Model
> Endpoint
API Gateway
[?] Select a endpoint to cleanup:: sych-llm-pg-meta-textgeneration-llama-2-7b-f-e-1692383398
> sych-llm-pg-meta-textgeneration-llama-2-7b-f-e-1692383398
Endpoint sych-llm-pg-meta-textgeneration-llama-2-7b-f-e-1692383398 cleaned up successfully.In the example above, an endpoint has been selected for removal. Once the command is executed, the tool confirms the successful deletion of the endpoint. This is part of the lifecycle management offered by sych-llm-playground, giving you control and flexibility to manage resources according to your needs and budget.
Coming Soon
We're actively working on enhancing the functionality of sych-llm-playground to provide an even more powerful and user-friendly experience. Our roadmap:
- Fine-Tuning Models: Soon, you'll be able to fine-tune your favorite language models directly through the CLI. This feature will streamline the process of adapting models to your specific use cases and requirements.
- Local Model Running: For those looking to work with models offline or in a restricted environment, we are planning to offer the ability to run selected models locally.
- Graphical User Interface (GUI): To cater to a wider audience, including those who prefer graphical interfaces, we're working on a GUI that will encompass all the existing CLI functionalities in an intuitive and visually appealing layout.
- Expand Support for Models: At the time of writing, this tool supports all Llama 2 models. We will be working on expanding support for other open source large language models in this tool.
We always welcome community input and collaboration. If you have feature requests, would like to contribute to this open-source project or are facing issues, please visit our GitHub repo. Your feedback and contributions can help us make sych-llm-playground even better and more aligned with the needs of researchers, developers, and AI enthusiasts!
Conclusion
sych-llm-playground provides an accessible and efficient way to deploy and interact with language models on the cloud. Through its interactive CLI tool, users can swiftly configure, deploy, interact, list, and clean up resources, all with simple commands. Whether you are a seasoned AI practitioner or simply curious about playing with language models, this tool is designed to simplify your experience.
Happy experimenting, and may your exploration of language models be both enlightening and enjoyable!